Web Site Archives
You know how the “Reader View” button in your browser will strip away everything but a page’s core content? Backup Brain takes the same approach to archives. It doesn’t try and store an exact copy of the page. It tries to extract the page’s central content and store that for you.
These archives are downloadable as Markdown files. The system also supports multiple historical archives of the same page, so you can capture its changes over time. A button to easily create a new archive of a bookmark’s site will be coming in v1.1.
What they look like
Here’s a side-by-side of a Tech Crunch page, and a view of the archive we created from it. As you can see, we’ve stripped out a lot of stuff that isn’t the core content of this page.
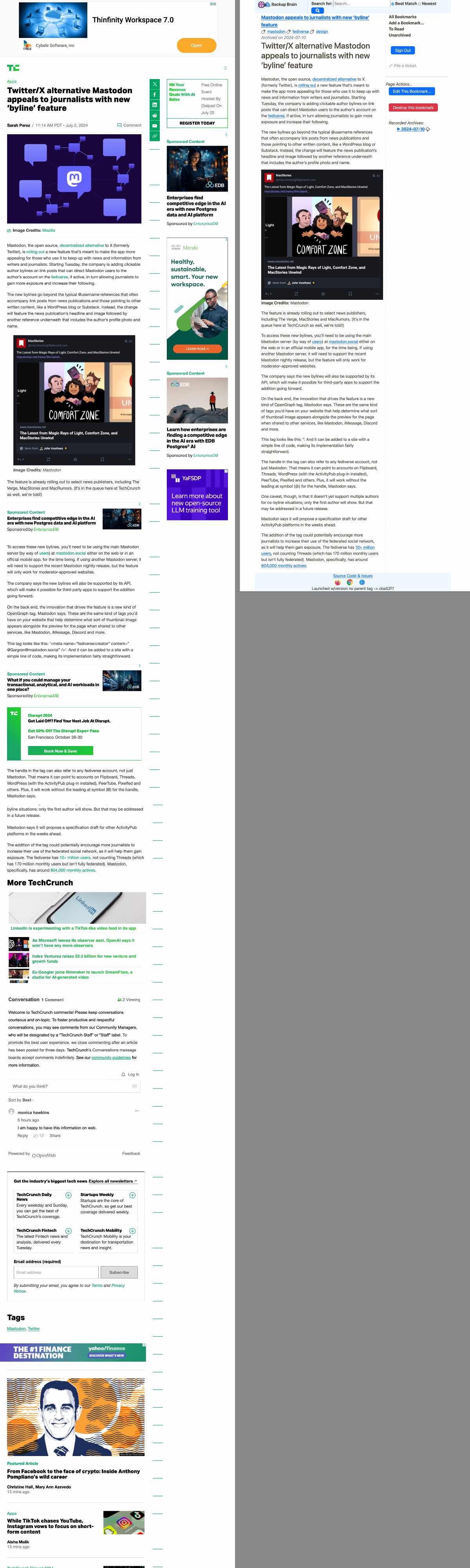
Techcrunch Original, and our Archived copy
Creating & Interacting With Archives
When you bookmark a page for the first time BB will queue up a background process to attempt to archive the web site. Usually this takes under 30 seconds.
When a bookmark has an archive you’ll see an archive icon with the word “Archived” beside it, and when it doesn’t you’ll see a little download icon with the words “Archive Now”
Clicking “Archived” will show you the most recent archive, and give you access to historical ones if there are any.
Clicking “Archive Now” will kick off try and get a copy of it again.
Archives are never deleted unless the bookmark is deleted. You can see a history of archives for a bookmark in the right side-bar.
Regenerating Archives
The following actions will not attempt to rearchive any Bookmark with three or more failed attempts at creating an archive, because it’s very unlikely that it’ll work the next time. You can still attempt to create an archive for a single unarchived page by clicking the “Archive Now” link next to it.
Depending on how many bookmarks you have these scripts can take minutes to run. Start them up, go get a drink, come back later. Just don’t close the terminal window until it has told you how many Bookmarks it managed to archive.
-
Rearchive ALL bookmarks
This is useful for getting a new snapshot in time of all your bookmarked pages.
You can add a new archive for all bookmarks from the command line by running the following command from your Backup Brain’s root directory.
bundle exec rake cleanup:rearchive_allThis will attempt to create a new archive for every bookmark.
As noted above, the ability to create a new bookmark for just one page is coming in v1.1.
-
Attempt to archive Unarchived Bookmarks
If your system was having trouble archiving pages, and you think the problem has been resolved, then you should probably run
bundle exec rake cleanup:retry_unarchived
Limitations
Content Limitations
Figuring out what constitutes the “content” on a web page is an incredibly tricky problem. The “readability” algorithm is what powers the “Reader View” in browsers. It decides what constitutes “content” by combining a bunch of “rules-of-thumb”. For example, if something’s in a <footer> element, or has a class named footer it’s probably not content.
It’s an imperfect solution. Sometimes it cuts out pieces you want. Sometimes it leaves in pieces you don’t.
We’re currently reliant on the capabilities of an external tool, but there is an open ticket to replace it, so that we can have more control and fix limitations as we encounter them. That’ll require building an entirely new Redability library for Ruby, so it’s going to be a little bit before that’s complete.
Download Limitations
- BB can’t download anything that’s hidden behind a login page.
- Generally we can’t retrieve the results of a form submission.
- Some sites simply refuse to let tools download web pages unless they go through a lot of gyrations to pretend to be a human using a browser. Creative Market, for example, always returns a 403 (Forbidden) code, even if the URL you’re trying to bookmark is allowed by their robots.txt.
- We can’t download from sites that are having problems at the moment.
- We can’t download from sites or pages that no longer exist. You’ll likely see a lot of of this if you import a bunch of old bookmarks.
As an aside: It’s unclear why some sites try so hard to keep bots from ingesting their content. The problem is so significant that there are multiple companies who provide really advanced bots that pretend to be real users in order to be able to download web pages that are public to begin with.
Robots.txt
Backup Brain does ignore robots.txt files. It also pretends to be Chrome instead of advertising itself as a well mannered robot should.
The thinking is that while it does technically count as a “robot” it’s also only every going to request one file, and it’s going to do it because a human manually requested it, and it’s only going to work if that were a page that the general public was allowed to see anyway. We’re also never going to use that data for profit or mislead people about where it came from. We literally only ever request a web page to create a personal backup.
I feel like we’re following the “intent” of the rule.
Troubleshooting
Please keep in mind the Limitations listed above. If Backup Brain can’t create an archive of a page it’s almost always because it requires a user to be logged in to view it, or the server is aggressively refusing access to anything that looks like an unknown bot.
Figuring out what went wrong
In v1.0 the only way to know why an archive attempt failed is to check the logs. There is a ticket for v1.1 to make it easy to see what went wrong.
If you look in log/development.log a failed job will have a line that looks like this. The important part is the “Remote server prevented download.” at its end.
couldn't archive https://example.com/page/i/bookmarked - Remote server prevented download. Status code: 403
You can look up the meaning of the status code at http.cat
Fixing it
If the error code indicates a problem requesting the document from the server, then there’s probably nothing we can do about it. See “Limitations” above.
If you’re not seeing an “couldn’t archive” message, or you’re seeing some other error, then please file a ticket and be sure to include the URL you were trying to bookmark.